
Most sysadmins and developers have at some point used a few of the popular Linux networking commands or their Windows equivalents to answer the common questions of host reachability - that is, whether a host or service is reachable and how fast it responds.
Common approaches to reachability
One of the simplest, common checks, is to simply ping a host to verify that it’s reachable from where you issue the command, and to see the total time it takes for the host to receive your request.
However, to go from a simple manual check executed once on a given node, to proactively monitoring host reachability, you need a proper monitoring tool. Netdata Cloud has the capability to send reachability notifications for any Netdata node that loses its connection to the cloud. You just need to change the notification settings of your personal profile to All Alerts and unreachable for every room you want to receive such notifications from:

But, of course, this isn’t really monitoring the reachability of the host itself.
Netdata monitors various components involved in the availability and performance of any service reached via a network protocol, such as name resolution, network interfaces, TCP/UDP packets, IPv4/IPv6 usage, Netfilter statistics, QoS, and more. Of course, it monitors host reachability and total network latency as well, utilizing ping.
ping is a Linux command line tool that monitors host reachability and measures round-trip time and packet loss by sending ping messages to network hosts.The instructions to install and configure the collector are available in the collector’s documentation, so let’s just dive into the benefits of this plugin.
Example using ping
In the example below, I’ve configured the ping plugin to monitor just two “hosts”, from a single location. The hosts configured can be IP addresses or the hostname itself, london.netdata.rocks and 10.20.128.1.
The first chart we see in the ping section is the ping latency.
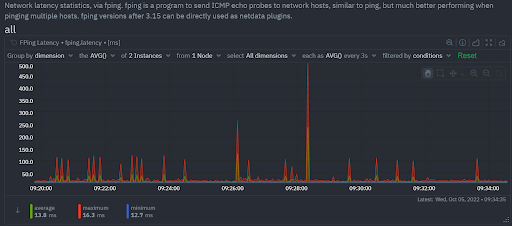
The default configuration of the chart is telling us that we’re seeing a grouping by dimension of metrics coming from two instances in one Node. Two hostnames monitored, so the instances make sense. But what you see here in the dimensions are average, maximum and minimum latencies for the request of all the ICMP request timings within the time frame depicted by that point. If we zoom in far enough, we’ll see that even when each point shows a single second, we still have different values for min, max and average. The reason we have so many values is that by default, the Netdata ping collector issues 5 ICMP requests with a 100ms interval, per host! Do take note of that: if your latency is too high to accommodate so many requests per second, you’ll need to modify the interval or packets in ping.conf.
This chart may be useful if I’m monitoring the reachability of many instances of the same service perhaps, but more often than not, I’d want to see how each host responds. So let’s change the view to Group by host.

Now you can see separate charts for each of the hosts which clearly show you the ping latency patterns for each host you are interested in.

Now, if instead of avg, min and max you just want to see the values for one of those dimensions (Eg: max) you can filter the chart to this effect as well. This might be useful in scenarios where you want to keep an eye on potential spikes in latency from certain hosts.

If more than the raw values of the ping latency itself you are interested in variations form the norm, there's another chart for you which is focused on the standard deviation in Ping RTT.

If any of the ping packets that you send do not reach their destination and are dropped along the network path, it contributes to packet loss. Packet loss can be caused by network congestion, hardware issues, software bugs, and a number of other factors.

The final chart that shows packets sent vs packets received can show us the absolute number of ping packets being sent and received per second.
Alert configurations
The Netdata ping plugin comes with built in alerts for the following conditions:
- Host unreachable
- Ping packet loss exceeds threshold
- Ping latency exceeds threshold
You can see the exact configuration of all alerts in /netdata/netdata/health/health.d/ping.conf, or by going to your netdata config directory and running /edit-config health.d/ping.conf. One alert you may want to customize based on your use case is the latency one, and specifically the number of milliseconds that triggers the alert. The default is shown below and has values exceeding 500 ms (avg last 10sec) to go to warning and 1000ms to turn critical. That may either be too strict, or too lenient for your use case.
template: ping_host_latency
families: *
on: ping.host_rtt
class: Latency
type: Other
component: Network
lookup: average -10s unaligned of avg
units: ms
every: 10s
green: 500
red: 1000
warn: $this > $green OR $max > $red
crit: $this > $red
delay: down 30m multiplier 1.5 max 2h
info: average latency to the network host over the last 10 seconds
to: sysadmin
So, if your hosts do permit ICMP requests, Netdata’s ping plugin has everything you need. But you still need to think about where you will be running such tests from. The obvious answer is to run them from a management node somewhere in your infrastructure. But, this is certainly not what your users will experience if your service is public. Ideally, you’d want to set up probes in many different places, depending on where your customers are.
With Netdata, it’s very easy to do that very cheaply, as it can be configured to utilize very limited resources. So you could get very cheap nodes and run a Netdata agent on each one of them. You might not even want to store the collected metrics locally on those nodes, but stream those metrics to a parent Netdata node. A parent child setup is always a good idea for production deployments anyway, for data replication.
Let us hear from you
If you haven’t already, sign up now for a free Netdata account!
We’d love to hear from you – if you have any questions, complaints or feedback please reach out to us on Discord or Github.
Happy Troubleshooting!